책소개
머신러닝 분야 부동의 베스트셀러! 트랜스포머와 LLM 실습까지 더 많이 채웠다!
케라스는 물론 파이토치까지, 혼자서도 1:1 과외하듯 배우는 인공지능 자습서
** 혼공 용어 노트, 저자 직강 유튜브 강의, FAQ(자주 하는 질문), 오픈 채팅 등 풀패키지 제공
『혼자 공부하는 머신러닝+딥러닝』 (개정판)은 머신러닝과 딥러닝의 핵심 개념을 쉽고 체계적으로 익힐 수 있도록 돕는 입문서로, 최신 AI 트렌드를 반영해 더욱 완성도를 높였다. 특히 트랜스포머와 대규모 언어 모델(LLM) 실습을 새롭게 추가하여, 최신 AI 기술이 실제로 어떻게 동작하는지 배울 수 있도록 했다.
1판에서 많은 독자의 사랑을 받았던 ‘1:1 과외하듯 배우는 설명 방식’과 ‘구글 코랩(Colab) 기반 실습’을 유지하면서, 파이토치 예제 코드를 보강했다. 또한, 각 장마다 ‘자주 하는 질문(FAQ)’ 코너를 추가해 학습자의 이해를 돕고, 실습 중 마주할 수 있는 오류나 개념적 궁금증을 쉽게 해결할 수 있도록 구성했다. 입문자가 실전에서 부딪히는 문제를 미리 경험하고 해결하는 능력을 키울 수 있어, 더욱 효과적으로 머신러닝과 딥러닝을 익힐 수 있다.
또한, 혼공 용어 노트, 저자 유튜브 강의, Q&A 커뮤니티 등 다양한 학습 지원을 제공해 혼자서도 끝까지 학습을 이어갈 수 있도록 돕는다. 최신 AI 개념을 이해하고 실습까지 제대로 해보고 싶다면, 지금 이 책을 만나보자.

저자소개

목차
Chapter 01 나의 첫 머신러닝
01-1 인공지능과 머신러닝, 딥러닝
인공지능이란
머신러닝이란
딥러닝이란
[키워드로 끝내는 핵심 포인트]
[이 책에서 배울 것]
01-2 코랩과 주피터 노트북
구글 코랩
텍스트 셀
코드 셀
노트북
[키워드로 끝내는 핵심 포인트]
[표로 정리하는 툴바와 마크다운]
[확인 문제]
01-3 마켓과 머신러닝
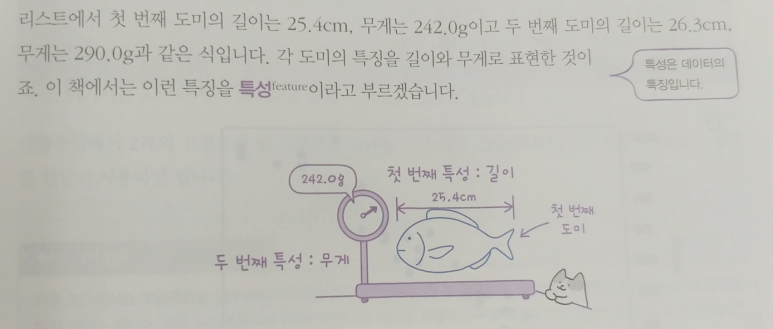
생선 분류 문제
첫 번째 머신러닝 프로그램
[문제해결 과정] 도미와 빙어 분류
[키워드로 끝내는 핵심 포인트]
[핵심 패키지와 함수]
[확인 문제]
[자주 하는 질문]
Chapter 02 데이터 다루기
02-1 훈련 세트와 테스트 세트
지도 학습과 비지도 학습
훈련 세트와 테스트 세트
샘플링 편향
넘파이
두 번째 머신러닝 프로그램
[문제해결 과정] 훈련 모델 평가
[키워드로 끝내는 핵심 포인트]
[핵심 패키지와 함수]
[확인 문제]
02-2 데이터 전처리
넘파이로 데이터 준비하기
사이킷런으로 훈련 세트와 테스트 세트 나누기
수상한 도미 한 마리
기준을 맞춰라
전처리 데이터로 모델 훈련하기
[문제해결 과정] 스케일이 다른 특성 처리
[키워드로 끝내는 핵심 포인트]
[핵심 패키지와 함수]
[확인 문제]
[자주 하는 질문]
Chapter 03 회귀 알고리즘과 모델 규제
03-1 k-최근접 이웃 회귀
k-최근접 이웃 회귀
데이터 준비
결정계수(R²)
과대적합 vs 과소적합
[문제해결 과정] 회귀 문제 다루기
[키워드로 끝내는 핵심 포인트]
[핵심 패키지와 함수]
[확인 문제]
03-2 선형 회귀
k-최근접 이웃의 한계
선형 회귀
다항 회귀
[문제해결 과정] 선형 회귀로 훈련 세트 범위 밖의 샘플 예측
[키워드로 끝내는 핵심 포인트]
[핵심 패키지와 함수]
[확인 문제]
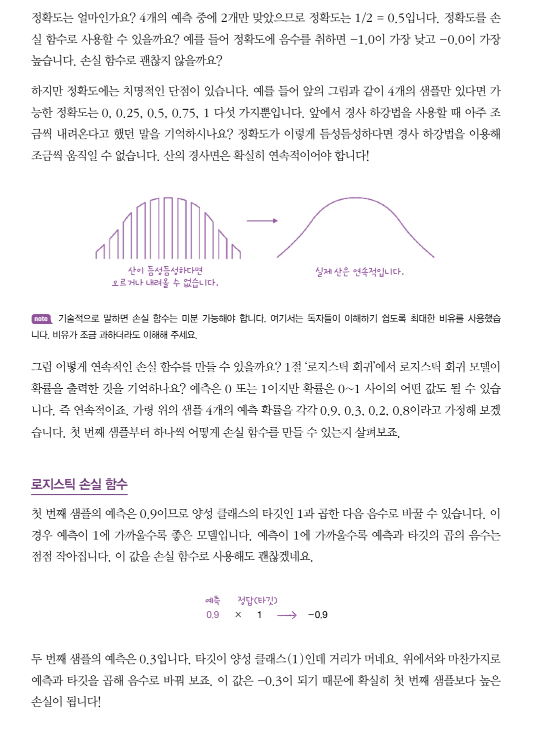
03-3 특성 공학과 규제
다중 회귀
데이터 준비
사이킷런의 변환기
다중 회귀 모델 훈련하기
규제
럿지 회귀
라쏘 회귀
[문제해결 과정] 모델의 과대적합을 제어하기
[키워드로 끝내는 핵심 포인트]
[핵심 패키지와 함수]
[확인 문제]
[자주 하는 질문]
Chapter 04 다양한 분류 알고리즘
04-1 로지스틱 회귀
럭키백의 확률
로지스틱 회귀
[문제해결 과정] 로지스틱 회귀로 확률 예측
[키워드로 끝내는 핵심 포인트]
[핵심 패키지와 함수]
[확인 문제]
04-2 확률적 경사 하강법
점진적인 학습
SGDClassifier
에포크와 과대/과소적합
[문제해결 과정] 점진적 학습을 위한 확률적 경사 하강법
[키워드로 끝내는 핵심 포인트]
[핵심 패키지와 함수]
[확인 문제]
[자주 하는 질문]
Chapter 05 트리 알고리즘
05-1 결정 트리
로지스틱 회귀로 와인 분류하기
결정 트리
[문제해결 과정] 이해하기 쉬운 결정 트리 모델
[키워드로 끝내는 핵심 포인트]
[핵심 패키지와 함수]
[확인 문제]
05-2 교차 검증과 그리드 서치
검증 세트
교차 검증
하이퍼파라미터 튜닝
[문제해결 과정] 최적의 모델을 위한 하이퍼파라미터 탐색
[키워드로 끝내는 핵심 포인트]
[핵심 패키지와 함수]
[확인 문제]
05-3 트리의 앙상블
정형 데이터와 비정형 데이터
랜덤 포레스트
엑스트라 트리
그레이디언트 부스팅
히스토그램 기반 그레이디언트 부스팅
[문제해결 과정] 앙상블 학습을 통한 성능 향상
[키워드로 끝내는 핵심 포인트]
[핵심 패키지와 함수]
[확인 문제]
[자주 하는 질문]
Chapter 06 비지도 학습
06-1 군집 알고리즘
타깃을 모르는 비지도 학습
과일 사진 데이터 준비하기
픽셀값 분석하기
평균값과 가까운 사진 고르기
[문제해결 과정] 비슷한 샘플끼리 모으기
[키워드로 끝내는 핵심 포인트]
[확인 문제]
06-2 k-평균
k-평균 알고리즘 소개
KMeans 클래스
클러스터 중심
최적의 k 찾기
[문제 해결 과정] 과일을 자동으로 분류하기
[키워드로 끝내는 핵심 포인트]
[핵심 패키지와 함수]
[확인 문제]
06-3 주성분 분석
차원과 차원 축소
주성분 분석 소개
PCA 클래스
원본 데이터 재구성
설명된 분산
다른 알고리즘과 함께 사용하기
[문제해결 과정] 주성분 분석으로 차원 축소
[키워드로 끝내는 핵심 포인트]
[핵심 패키지와 함수]
[확인 문제]
[자주하는 질문]
Chapter 07 딥러닝을 시작합니다
07-1 인공 신경망
패션 MNIST
로지스틱 회귀로 패션 아이템 분류하기
인공 신경망
인공 신경망으로 모델 만들기
인공 신경망으로 패션 아이템 분류하기
[문제해결 과정] 인공 신경망 모델로 성능 향상
[키워드로 끝내는 핵심 포인트]
[핵심 패키지와 함수]
[확인 문제]
07-2 심층 신경망
2개의 층
심층 신경망 만들기
층을 추가하는 다른 방법
렐루 함수
옵티마이저
[문제해결 과정] 케라스 API를 활용한 심층 신경망
[키워드로 끝내는 핵심 포인트]
[핵심 패키지와 함수]
[확인 문제]
[파이토치 버전 살펴보기]
07-3 신경망 모델 훈련
손실 곡선
검증 손실
드롭아웃
모델 저장과 복원
콜백
[문제해결 과정] 최상의 신경망 모델 얻기
[키워드로 끝내는 핵심 포인트]
[핵심 패키지와 함수]
[확인 문제]
[파이토치 버전 살펴보기]
[자주 하는 질문]
Chapter 08 이미지를 위한 인공 신경망
08-1 합성곱 신경망의 구성 요소
합성곱
케라스 합성곱 층
합성곱 신경망의 전체 구조
[문제해결 과정] 합성곱 층과 풀링 층 이해하기
[키워드로 끝내는 핵심 포인트]
[확인 문제]
08-2 합성곱 신경망을 사용한 이미지 분류
패션 MNIST 데이터 불러오기
합성곱 신경망 만들기
모델 컴파일과 훈련
[문제해결 과정] 케라스 API로 합성곱 신경망 구현
[키워드로 끝내는 핵심 포인트]
[핵심 패키지와 함수]
[확인 문제]
[파이토치 버전 살펴보기]
08-3 합성곱 신경망의 시각화
가중치 시각화
함수형 API
특성 맵 시각화
[문제해결 과정] 시각화로 이해하는 합성곱 신경망
[키워드로 끝내는 핵심 포인트]
[핵심 패키지와 함수]
[확인 문제]
[파이토치 버전 살펴보기]
[자주 하는 질문]
Chapter 09 텍스트를 위한 인공 신경망
09-1 순차 데이터와 순환 신경망
순차 데이터
순환 신경망
셀의 가중치와 입출력
[문제해결 과정] 순환 신경망으로 순환 데이터 처리
[키워드로 끝내는 핵심 포인트]
[확인 문제]
09-2 순환 신경망으로 IMDB 리뷰 분류하기
IMDB 리뷰 데이터셋
순환 신경망 만들기
순환 신경망 훈련하기
단어 임베딩을 사용하기
[문제해결 과정] 케라스 API로 순환 신경망 구현
[키워드로 끝내는 핵심 포인트]
[핵심 패키지와 함수]
[확인 문제]
[파이토치 버전 살펴보기]
09-3 LSTM과 GRU 셀
LSTM 구조
LSTM 신경망 훈련하기
순환층에 드롭아웃 적용하기
2개의 층을 연결하기
GRU 구조
GRU 신경망 훈련하기
[문제해결 과정] LSTM과 GRU 셀로 훈련
[키워드로 끝내는 핵심 포인트]
[핵심 패키지와 함수]
[확인 문제]
[파이토치 버전 살펴보기]
[자주 하는 질문]
Chapter 10 언어 모델을 위한 신경망
10-1 어텐션 메커니즘과 트랜스포머
순환 신경망을 사용한 인코더-디코더 네트워크
어텐션 메커니즘
트랜스포머
셀프 어텐션 메커니즘
층 정규화
피드포워드 네트워크와 인코더 블록
토큰 임베딩과 위치 인코딩
디코더 블록
[키워드로 끝내는 핵심 포인트]
[확인 문제]
10-2 트랜스포머로 상품 설명 요약하기
트랜스포머 가계도
전이 학습
BART 모델 소개
BART의 인코더와 디코더
허깅페이스로 KoBART 모델 로드하기
텍스트 토큰화
[키워드로 끝내는 핵심 포인트]
[핵심 패키지와 함수]
[확인 문제]
10-3 대규모 언어 모델로 텍스트 생성하기
디코더 기반의 대규모 언어 모델
LLM 리더보드
EXAONE의 특징
EXAONE-3.5로 상품 질문에 대한 대답 생성하기
토큰 디코딩 전략
오픈AI 모델의 간략한 역사
오픈AI API 키 만들기
오픈AI API로 상품 질문에 대한 대답 생성하기
[키워드로 끝내는 핵심 포인트]
[핵심 패키지와 함수]
[확인 문제]
부록 한 발 더 나아가기 : 이 책에 대한 독자의 질문
출판사리뷰
머신러닝과 딥러닝을 한 권으로 처음부터 끝까지 배우고 싶을 때
수식 없이 직관적으로 개념을 익히고 싶을 때
혼자서도 실습하며 AI 모델을 구현해 보고 싶을 때
》 하나, ‘입문자 맞춤형 학습 설계’로 개념과 실습을 함께 익힌다!
이 책은 머신러닝과 딥러닝을 처음 배우는 학습자를 위한 맞춤형 학습 설계로 구성되었다. 개념을 쉽게 이해할 수 있도록 스토리텔링 방식의 설명과 직관적인 비유를 활용하며, 모든 실습은 구글 코랩(Colab) 환경에서 바로 실행할 수 있도록 제공한다. 또한, 개정판에서는 각 장마다 ‘자주 하는 질문(FAQ)’ 코너를 추가하여 학습자의 궁금증을 바로 해결할 수 있도록 했다.
》 둘, 최신 AI 기술까지 다루는 확장된 실습 범위!
기존의 머신러닝 및 딥러닝 개념을 탄탄히 다지는 것은 물론, 개정판에서는 트랜스포머와 대규모 언어 모델(LLM) 실습을 새롭게 추가했다. 또한, 독자 요청이 많았던 파이토치 예제 코드를 보강해, 케라스뿐만 아니라 파이토치까지 함께 익힐 수 있도록 구성했다.
》 셋, 혼자서도 끝까지 학습할 수 있도록 [용어 노트], [유튜브 강의] 등 다양한 학습 지원 제공!
책을 읽으며 학습을 이어갈 수 있도록 혼공 용어 노트, 저자 유튜브 강의, Q&A 커뮤니티, 독자 전용 오픈 채팅 등을 지원한다. 어려운 개념이 나오더라도 언제든 참고할 수 있도록 복습 자료를 제공하며, 궁금한 점은 온라인 커뮤니티에서 해결할 수 있도록 했다.
▶ 학습 사이트: https://hongong.hanbit.co.kr
》 넷, 실습과 개념을 균형 있게 익히고 싶은 모든 학습자를 위한 책!
이 책은 머신러닝과 딥러닝을 처음 배우려는 입문자, AI 실습을 통해 직접 모델을 구현해 보고 싶은 개발자, 최신 AI 기술을 익히고 싶은 실무자까지 모두에게 적합한 학습서다. 머신러닝과 딥러닝을 체계적으로 익히고 싶다면, 지금 이 책을 만나보자.
오탈자 등록