한빛미디어 서평단 <나는리뷰어다> 활동을 위해서 책을 협찬 받아 작성된 서평입니다.
시작하기 전에...
? 이 책을 어떻게 리뷰하면 좋을까?
이 책에 담긴 내용이 너무나 소중해서 어떻게 다루어야할지 고민을 정말 많이 했다. G1 / Shenandoah / ZGC / Balanced 등 고급 GC의 원리와 활용 방법을 바로 다루자니 비교적 마이너한 분야라 처음 접하시는 분들이 읽기에는 피로도가 높을 것 같았고, 반대로 애플리케이션 관측성과 클라우드 배포를 실습하자니 제품 활용에 대한 내용이 많아 이 책의 진가를 보여줄 수 없을 것 같았다. 그래서 고민 끝에 Java 성능 향상을 위해 하드웨어에 대한 기계적 공감이 얼마나 중요한지를 핵심 주제로 정했다. 물론 글의 흐름에도 신경썼다. 하드웨어에 대한 내용은 동시성에 대한 상세 내용 자체는 7장에서 30페이지 이하로 짧게 작성되었지만, 나는 이 짧은 내용조차 책 전반에 걸쳐 얼마나 깊이 있게 이해할 수 있는지를 전달하고 싶었다. 따라서, 7장에만 국한되지 않고 필요하다면 이전/이후 장의 내용들을 유기적으로 짜깁기하여 저자의 의도가 파편화되지 않도록 보충했다. 각 문단 끝에 ? 이모지를 활용하여 작성 의도를 요약하였으니, 모든 내용을 읽기 어렵다면 이 부분만 가볍게 체크하고 넘어가면 된다.


자바 최적화 / 벤저민 에번스, 제임스 고프 지음 / 한빛미디어
1. 당신이 하드웨어에 관심을 가져야 하는 이유
트랜지스터는 더 이상 작아질 수 없는 한계에 도달했으며, 결국 물리학의 법칙이 장애물로 작용합니다. 현재 트랜지스터는 원자 단위로 측정할 수 있을 정도로 작아졌고, 상용화된 가장 작은 트랜지스터의 너비는 3nm에 불과합니다. 이는 인간 DNA 한 가닥(약 2.5nm)보다 약간 더 넓은 수준입니다.
2021년, IBM은 2nm 칩을 성공적으로 개발했다고 발표했지만, 이제 이러한 발전은 비용이 과도하게 증가하고 진행 속도가 매우 느려졌습니다. 따라서 안정적인 성능 향상이 가능할지 의문이 제기되고 있습니다. 또한, 현재 재료 물리학의 한계를 고려하면 원자보다 얇은 전선을 만들 수는 없습니다.
─ Audrey Woods, 'The Death of Moore’s Law'
지난 수십년 간, 소프트웨어 성능은 하드웨어의 발전이 가져다주는 혜택 아래에서 쉽게 개선되어 왔다. 흔히 말하는 스케일 업(scale-up)을 통해 서버의 스펙을 높이면 처리량도 그에 비례하여 올라갔다. 그러나 어느 순간부터 스케일 업은 한계를 마주하게 된다. 하드웨어의 양적 개선만으로는 다양한 병목을 해결할 수 없었고, 하드웨어의 발전도 예전 같지 않았기 때문. 물론 예나 지금이나 한결 같이 개선의 한계를 토로했음에도 기술은 끊임없이 발전해왔다. 그러나 그 속도는 예전 같지 않음에 동의하지 않을 사람은 없다. 반도체 집적회로의 성능이 24개월마다 2배로 증가한다는 무어의 법칙(Moore's law)도, 이제는 무어의 제2법칙에서 48개월로 늘어났다.
따라서 현대 컴퓨터에서는 자연스럽게 한정된 트랜지스터를 효율적으로 활용하기 위한 고도화가 진행되었다. 예전에는 단순 스케일 업으로 향상되었던 하드웨어 성능도, 이젠 기술적/경제적 이유로 인해 구조적 개선이 불가피하다는 뜻이다. 그렇다면 소프트웨어는 어떨까? 소프트웨어 프레임워크도 이에 발맞춰 개선하다보니 복잡성이 증가했다. 정리하자면 결과적으로 컴퓨팅 성능 자체는 분명 향상되었지만, 소프트웨어 엔지니어가 이 혜택을 모두 누리기 위해 알아야 할 지식과 수행해야 할 작업들이 예전에 비해 점점 더 복잡해지고 있다는 것이다.
? 단순 스케일 업 기반의 성능 향상은 한계에 도달했다. 이제 소프트웨어 엔지니어들은 현대 하드웨어의 개선 방향성과 이를 기반으로 최적화된 언어 및 프레임워크의 동작을 이해해야만 최고 수준의 성능 최적화에 도달할 수 있다.
? The Death of Moore’s Law: What it means and what might fill the gap going forward
? The Free Lunch Is Over: A Fundamental Turn Toward Concurrency in Software
2. 지금 당장 하드웨어를 활용해야 하는 이유
JVM (Java Virtual Machine)
당신이 자바 가상 머신(JVM)을 활용하는 소프트웨어*를 개발하고 있다면, JVM이 멀티 코어 프로세서에 최적화된 방식으로 동작한다는 사실을 명심해야 한다. JIT 컴파일러(Just-in-time Compiler), 그리고 프로덕션 환경에서 사용하는 현대의 GC(Garbage Collection) 모두 해당된다. 당신이 작성한 애플리케이션이 싱글 스레드에 Blocking 방식으로 동작하든, 멀티 스레드에 Non-blocking 방식으로 동작하든 상관 없다. 현대의 자바 실행 환경은 멀티 코어 환경에 최적화됐다. 그럼에도 2022년 Relic의 조사에 따르면, 자바 애플리케이션의 70% 이상이 컨테이너 환경에 배포되고 있었으며, 그 중 약 절반은 1 vCPU 이하로 제한된 상태에서 실행되고 있었다.
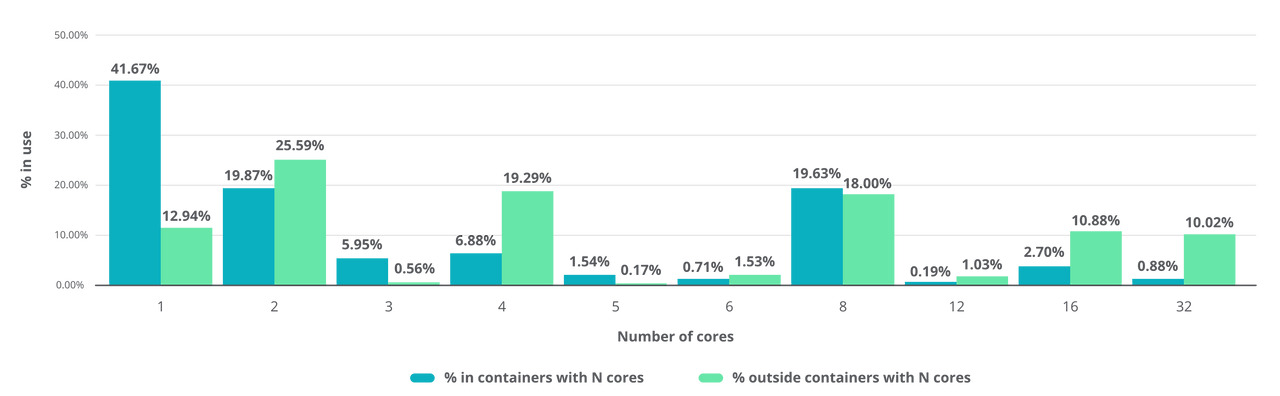
Relic - 2022 State of the Java Ecosystem
이것은 결코 사소하지 않다. 레드햇과 마이크로소프트의 연구 결과에 따르면, 자바 애플리케이션을 컨테이너화할 때 다수의 단일 코어 컨테이너보다 소수의 멀티 코어 컨테이너에서 실행하는 것이 일반적으로 더 유리한 것으로 나타났다. 이러한 싱글 코어 제약은 JVM이 Serial 또는 SerialOld 컬렉터를 선택하도록 만들고 GC가 직렬로 실행되도록 만들어, 일시 정지 시간이 길어지고 처리량이 줄어들며 애플리케이션이 더 빈번하게 중단되는 문제를 야기한다. 그래도 이듬해 23년 Relic의 조사 결과에서는 이런 케이스가 5%p 가량 감소했다.

Java 11과 17에서 CPU 2개 이상, 메모리 2GB 이상이 아니라면 Serial GC가 선택된다
? 기본적인 GC 최적화도 제대로 이루어지지 않고 있는 것이 현실이다. 복잡한 튜닝 없이 기본 원칙을 지키는 것만으로 애플리케이션 성능이 배가 된다면... 하지 않을 이유가?
* Java로 언어를 특정하지 않은 이유는 JVM은 유효한 클래스 파일을 생성할 수 있는 모든 언어에 호환되기 때문이다. 일례로 Kotlin, Groovy, Scala, Clojure 등이 생성하는 바이트코드는 모두 JVM 위에서 실행 가능하다.
? 2022 State of the Java Ecosystem / 2023 State of the Java Ecosystem
? Best practices for Java in single-core containers
앞선 멀티 코어 프로세서 사례를 통해 성능 최적화를 하드웨어 영역에서 바라보는 것이 왜 중요한지, 실증적인 문제 인식은 충분히 되었을거라 믿는다. 물론 전력 효율이나 메모리 최소화 등의 특수한 경우에는 싱글 코어 환경이 적합할 수도 있지만, 우리는 지금 일반적인 얘기를 하고 있다. 문제는 단순히 안티 패턴을 교정하는 수준이 아니라, 성능 최적화를 위한 파인 튜닝이 필요할 때다. 안타깝게도 이를 위한 은탄환은 없다. 따라서, 다음 단계는 런타임동안 JVM이 어떻게 동작하는지 이해하고, 가설을 세운 뒤 이를 검증하는 것이다. 이러한 관점에서 JIT 컴파일러와 GC는 학습을 위한 좋은 출발점이다. C1, C2 계층적 컴파일, 메서드 캐시와 코드 캐시, 분기 예측과 추측 실행, AOT 컴파일과 PGO 등 처리 속도 관점에서 학습하고, 클래식 GC부터 G1, 섀넌도어의 구조와 동작 방식 등 런타임 상태 분석 관점에서 학습해볼 수 있다.



JVM 이해를 돕는 다양한 도식들
3. 자바 메모리 모델이 중요한 이유
'갑자기 메모리?' 라고 생각했다면 주목. 앞선 두 문단에 걸쳐 나는 하드웨어 자체의 발전 속도에는 제동이 걸렸으니, 이제는 보다 자원을 똑똑하게 활용해야 할 때라는 메세지를 전달하고 싶었다. 이러한 관점에서 동시성 프로그래밍을 활용하는 것이야말로 시스템 자원을 똑똑하게 활용하는 방법 중 하나라는 데에 이의를 가진 독자는 없을거라 생각한다. 또한 이 글 전반에 걸쳐 강조하고 싶은 내용은 코드 레벨 외에도 JVM의 동작을 이해하는 것으로 가능한 최적화가 있다는 사실이다. 중요하게 생각하는 동시성 프로그래밍과 JVM, 둘 사이의 교집합으로 JMM이 존재하기에 강조하고자 했으며, 이를 보다 깊이있게 전달하기 위해 컴퓨터 구조가 어떻게 개선되어 왔는지부터 간단히 짚고 넘어가도록 하겠다.
CPU 발전과 캐시의 도입
CPU는 계속 발전해왔다. 무어의 법칙 아래 트랜지스터 수는 기하급수적으로 증가했고, 클럭 속도도 따라서 상승했다. 문제는 데이터였다. 데이터가 다음 클럭에 바로 로드되지 않아(hazard) CPU가 정지(stall)하는 상황이 빈번해졌다.* 정리하자면 메모리에 병목이 걸려 전체 성능이 메모리 성능 수준에 머물게 되는 것이다.

연도별 프로세서-메모리 성능. 차이가 커질수록 데이터 로드 지연에 따른 연산 효율은 감소한다.
이러한 현상은 '폰 노이만 병목'으로도 불리며, 폰 노이만 컴퓨터 구조에서 명령어와 데이터가 동일한 버스를 공유하기 때문에 발생한다. CPU 캐시는 이를 완화하기 위한 방법 중 하나로 도입되었다. 핵심 컨셉은 자주 접근하는 메모리의 위치와 값을 근처에 복사해두고 사용해서 최대한 주 메모리 참조 횟수를 줄이는 것. 프로세서 아키텍처에 따라 캐시의 수와 구성에 다소 차이가 있지만, 일반적으로 L1과 L2는 각 코어 내부에, L3는 여러 코어가 공유하도록 구성되어 있다. 이 결과로 소프트웨어의 성능은 참조 데이터의 지역성 수준 정도로 이전보다 수십 배 빨라질 수 있게 되었다.


* 물론 단순 대기(stall) 외에도 이러한 비효율을 방지하기 위한 다양한 개선책─operand forwarding, scoreboarding, Tomasulo algorithm이 존재한다. 하지만 여기서는 캐싱을 통한 구조적 개선만 다룬다.
캐시가 만든 새로운 문제들
그렇게 문제가 사라졌다면 좋았겠지만, 안타깝게도 멀티 코어 시스템에서는 또 다른 문제들이 발생했다. 각 CPU 코어가 데이터를 캐시에 저장하고 독립적으로 처리하다 보니, 동일한 메모리 위치에 대해 서로 다른 값을 갖는 상황이 발생했다. 이미 로드한 값을 주 메모리 참조 없이 재사용하는 것이 성능 향상의 핵심이라면, 다른 프로세서에서 주 메모리 값을 수정해야 한다면 어떻게 처리해야 할까? Write-through? Write-back? MESI 프로토콜은 또 뭐지? 또 여러 CPU가 동일한 메모리 위치를 어떻게 일관되게 접근할 수 있을까? 강한 메모리 모델과 캐시 무효화 알림? 약한 메모리 모델? 분명 x86 아키텍처에서 volatile 키워드 제대로 동작했는데, 왜 ARM에서는 결과가 이상하지? Race condition? Stall? Reordering? Operand Forwarding? ... ? 소프트웨어 개발은 언제 하지? 하지만 이러한 하드웨어 수준의 문제를 소프트웨어 개발자가 매번 신경 써야 한다면, 개발의 복잡도는 감당할 수 없는 수준이 된다. 이러한 문제를 해결하기 위해 하드웨어 수준의 문제들이 소프트웨어로 전파되지 않도록 고안된 추상화 계층, 자바 메모리 모델(JMM)이 등장했다.
자바 메모리 모델(JMM)
JMM은 복잡한 하드웨어 현실과 소프트웨어 세계를 격리시키기 위해 프로그래밍 모델로 추상화된 규약이다. 그러니까 JVM이 준수해야 하는 일종의 표준 계약(요구사항)인 셈이다. JSR-133을 보면 가시성(visibility), 원자성(atomicity), 순서 매기기(ordering) 등의 용어들과 synchronized, volatile, final과 같은 키워드들의 의미를 'happens-before' 관계를 중심으로 표준화했다. 실제로 문제를 해결하는 주체는 JVM 구현체이지만, 그 어떤 JVM도 JMM의 premise를 어길 수 없다는 사실은 이해하는 것은 스레드 간 공유 상태의 격리 수준을 최소화하는데 중요하다. 예를 들면, synchronized는 상호 배제와 happens-before 동시에 보장하는데, 대부분의 경우 이는 필요 이상의 과도한 오버헤드를 발생시킨다. 가령, boolean형 클래스 변수의 할당 연산을 동기화한다면 가시성만 보장하는 volatile의 사용을 고려해볼 수 있다. 즉, JMM에 대한 이해는 정확성과 성능 사이의 균형점을 찾기 위한 기초 지식이다. JVM 구현체는 하드웨어와의 접점에서 JMM을 준수하도록 설계되어 있고, 개발자는 이를 활용하여 정교한 동시성 설계와 최적화를 구현할 수 있다.

JSR-133: JMM은 주어진 프로그램의 실행 트레이스가 해당 프로그램 기준에서 '적법'한지 판별한다.
? 하드웨어의 구조적 특징이 동시성 프로그래밍에서 어떤 문제를 야기할 수 있는지 이해해야 한다. JMM이 도입된 이유에 공감하고, 'happens-before' 기반의 premise를 이해한다면 보다 깊이 있는 최적화가 가능해진다.
? JSR-133: JavaTM Memory Model and Thread Specification
? The JSR-133 Cookbook for Compiler Writers
? Close Encounters of The Java Memory Model Kind
4. 마치며...
현대의 자바 개발자들은 거대한 추상화의 혜택 위에 있다. 너무 익숙해져서 그 사실을 간과하고 있는 걸지도 모른다. 분명 성능 최적화는 첨단의 영역이지만, 그 내공은 컴퓨터 과학의 기본기에서 나온다는 것을 잊어서는 안 되겠다. 또 하드웨어를 포함한 소프트웨어의 실행 환경을 이해하는 것이 개발자에게 얼마나 큰 지평을 열어주는지 새삼 체감하게 된 시간이었다.
이렇듯 담고 있는 내용도 좋았지만, 이 책의 구성과 표현도 흥미로웠다. Java가 어떤 문제를 어떻게 해결해왔는지, 그 흐름을 쉽게 따라갈 수 있도록 도와준다. 서로 다른 영역의 내용들이 '성능 최적화'라는 주제를 중심으로 유기적으로 연결되어 있었고, 서사에 부여된 연역적인 연속성이 흥미를 돋워 처음 읽었을 때와 반복해서 읽었을 때의 느낌이 달라 정말 재밌었다.
이외에는 책이 컬러로 인쇄되어 코드를 포함하여 책의 가독성이 매우 좋고, 각주로 포함된 링크도 많아 깊게 파고들기 수월했다. 이 책의 단점은 가끔 오역인 것 같은 부분이 있다는 점 ─ 가령, CPU에서 다음 클럭에 데이터가 로드되지 않았으면 stall 상태가 되는데, 이를 유휴 상태로 표현하는 것은 적절하지 않은 것 같다. ─ 그리고 잘 읽다보면 책에 오타가 꽤 많고, 어떤 링크들은 접속할 수 없다는 점이다.
마지막으로 다시 한 번 강조하지만 이 책이 내용은 어려워도, 신기하게 정말 쉽게 읽힌다. 경력 관계 없이 자바 개발자라면 반드시 읽는 것을 추천한다.
* 이 책 외에도 다음과 같은 레드햇 자료들을 참고하면 더 많은 인사이트를 얻을 수 있다.









